I just released version 0.12.1, along with binary downloads at the usual place.
The main feature of this new version is that puppetresources can now detect dead code. In order to do so, you must supply it with a site.pp containing explicit references to all the nodes you are using, and run it that way :
1
puppetresources -p . -o deadcode +RTS -N4
Also of interest for those writing automated integration test, puppetresources now exits with an error code when something went wrong.
It seems to compile fine against GHC 7.6.3, even though I couldn’t really test the resulting executable (I gave a shot at Nix, but hruby is somewhat broken as a result).
This release doesn’t bring much on the table apart from an hypothetical 7.8 compatibility.
I made several claims of performance increase, previously, so here are the results :
0.10.5
0.10.6
0.11.1
0.12.0
49 nodes, N1
10.74s
9.76s
9.03s
49 nodes, N2
10.48s
7.66s
7.01s
49 nodes, N4
9.7s
6.89s
6.37s
49 nodes, N8
12.46s
13.4s
11.77s
Single node
2.4s
2.24s
2.02s
1.88s
The measurements were done on my workstation, sporting a 4 cores HT processor (8 logical cores).
The performance improvements can be explained in the following way :
Between 0.10.5 and 0.10.6, the Ruby interpreter mode of execution was modified from a Channel based system to an MVar one.
Between 0.10.6 and 0.11.1, all systems that would run on their own thread were modified to use the calling thread instead, reducing synchronization overhead (except for the Ruby thread). This gave a 9% performance boost for single threaded work, and a 29% performance boost when using four cores. The 8-cores performance worsened, because of the wasted work of the parser (This is explained in the previous post).
Between 0.11.1 and 0.12.0, I moved from GHC 7.6.3 to GHC 7.8-rc1, and bumped the version of many dependencies (including text and aeson, both having received a speed boost recently). This resulted in a “free” 7% speed boost.
As it is shown here, the initial parsing is extremely costly, as computing the catalogs for 49 nodes is about 5 times as long as computing it for a single node. As the parsed files get cached, catalog computing becomes more and more effective (about 50 times faster than Puppet). I don’t think the current parser can be sped up significantly without ditching its readability, so this is about as fast as it will get.
The next goals are a huge simplification of the testing system, and perhaps an external DSL. There are compiled binaries and ubuntu packages at the usual place.
This is a quick update, that mainly fixes the build issues with strict-base-types (it was updated a few minutes after I released v0.11.0). I also reduced the boilerplate (thanks redditors), and dropped all unsafeCoerce, as they had almost no effect on performance.
There is an important performance improvement however : filecache isn’t built around the ‘fork a master thread and communicate with it through a Chan’ pattern that I have been so fond of. As a quick reminder, the query function looks like that :
The first parameter is a file cache of actions of type a, that can fail with errors of type r. The second argument is the file path corresponding to the cache entry you are querying (note that nothing in this API forces a relationship between the file and the computation). The last argument is the IO action that should be cached. If the action has already been queried, and the file hasn’t changed since, then a cache hit should occur, and a quick answer is expected. The problem with the previous implementation was that, on cache misses, the action would be executed in the ‘master’ thread, blocking all other consumers of the file cache.
This is no longer the case, as this was all replaced by classic STM operations. This increased the performance a bit for the single threaded case, and a bit more with -N4. This is however a performance killer with -N8, as all threads query the same files at the same time, duplicating work unnecessarily. This was not a problem with the previous implementation, as only the first call would trigger the action, and all subsequent calls would hit the cache. All in all, this is simpler to reason about, and a nice gain in common situations.
There were a few hurdles to get there. The move from Data.Attoparsec.Number to Data.Scientific for number representation was not a big problem (even though code in hruby could be polished), but the lens and parsers upgrade proved more problematic.
Lens related breakage
The main problem with lens 4 was that it broke strict-base-types. I don’t think this will last long, but here is a temporary workaround for the impatient. Other than that, several instances of x ^. contains y were replaced by x & has (ix y) for the map-like types. This was a painless upgrade.
The trouble with parsers
I like this package a lot, because it exposes a nice API and supports several underlying parsers. But it comes with a couple problems.
The first one is related to the TokenParsing typeclass. This let you define how someSpace, the function that skip spaces, is defined. Unfortunately, the parsers library comes with an instance for parsec that will skip the characters satisfying isSpace. While this certainly is a sane choice, this is a problem for people who would like to use parsec as the underlying parser, but with a different implementation of someSpace. In my case, I also wanted to skip single line (start with #) and multi-line (/* these */) comments. A solution is to create a newtype, and redefine all instances. For those wondering how this is done, here is the relevant part. Please let me know if there is a way to do that that does not require that much boilerplate.
The second problem is that the expression parser builder (at Text.Parser.Expression) is much slower than what is in parsec. Switching to it from Text.Parsec.Expr resulted in a 25% slowdown, so I switched back to parsec. Unfortunately, I didn’t immediately realize this was the culprit, and instead believed it a case newtypes lowering performance. My code is now littered with unsafeCoerces, that I will remove in the next version (provided this does not result in a performance hit).
New features of previous versions I did not blog about
An ‘all nodes’ testing mode was added for puppetresources. This can be used that way :
1234567891011
$ puppetresource -p . -o allnodes +RTS -N4
Problem with workstation.site : template error for userconfig/signature.erb :
undefined method `[]' for nil:NilClass
(erb):5:in `get_binding'
/home/bartavelle/.cabal/share/x86_64-linux-ghc-7.6.3/language-puppet-0.11.0/ruby/hrubyerb.rb:46:in `get_binding'
/home/bartavelle/.cabal/share/x86_64-linux-ghc-7.6.3/language-puppet-0.11.0/ruby/hrubyerb.rb:68:in `runFromContent'
/home/bartavelle/.cabal/share/x86_64-linux-ghc-7.6.3/language-puppet-0.11.0/ruby/hrubyerb.rb:63:in `runFromFile'
in ./modules/userconfig/templates/signature.erb at # "./modules/userconfig/manifests/init.pp" (line 33, column 9)
Problem with db.dev.site : The following parameters are unknown: (use_ramdisk) when including class percona at # "./manifests/site.pp" (line 956, column 10)
Problem with db2.dev.site : The following parameters are unknown: (use_ramdisk) when including class percona at # "./manifests/site.pp" (line 969, column 9)
Tested 54 nodes.
This should provide a nice overview of the current state of your manifests. And it tested those nodes about 50 times faster than Puppet can compile the corresponding catalogs.
Behind the scene changes
The Puppet.Daemon machinery has been simplified a lot. It previously worked by spawning a pre-determined amount of threads specialized for parsing or compiling catalogs. The threads communicated with each other using shared Chans. The reason was that I wanted to control the memory usage, and didn’t want to have too many concurrent threads at the same time. It turns out that most memory is used by the parsed AST, which is shared using the (filecache)[http://hackage.haskell.org/package/filecache] module, so this is not a real concern.
I did rip all that, and now the only threads that is spawned is an OS thread for the embedded Ruby interpreter, and an IO thread for the filecache thread. The user of the library can then spawn as many parallel threads as he wants. As a result, concurrency is a bit better, even though there are still contention points :
The parsed file cache is held by the filecache thread, and communicates with a Chan. I will eventually replace this with an MVar, or some other primitive that doesn’t require a dedicated thread.
The Lua interpreter requires a LuaState, that should not be used by several threads at once. It is stored in a shared MVar.
The Ruby interpreter is the main performance bottleneck. It is single threaded, and very slow. The only way to speed it up would be to parse more of the ruby language (there is a parser for common Erb patterns included !), or to switch to another interpreter that would support multithreading. Both are major endeavors.
Waiting around the corner
The next releases will probably be Ruby 2.1 support for hruby, and some performance work on filecache.
I added a few prisms and a lens to language-puppet. I use it mainly for manipulating manifest files. Here is an example, with some ‘type annotation’ that should give an idea on how this work :
I recently needed a specific kind of publish-subscribe primitive, where the publisher must not block, and that should
not leak memory. It is published as the stm-firehose package.
It exposes an STM interface (built upon TBMQueue), but also higher level helpers. My use case is to be able to
tap on a message stream at will, and observe some of the messages as they flow through the infrastructure. The clients
will join and leave at any time, possibly from a low bandwidth connection. This means that they might not be able to
cope with the traffic, but this should not adversely affect the publisher or other clients.
firehoseApp: creates a WAI application that lets firehose clients connect through a web interface.
firehoseConduit: spawns a WARP server waiting for clients to connect, and returns a Conduit that will make all
messages traversing it available to clients.
Finally, a specialized version of firehoseConduit, called firehose, has been included in the
Data.Conduit.Firehose module of
the hslogstash package, in the name of fireHose. This version is specialized for querying logstash messages, and
yes, the naming of the function and module could have been better.
It might have been a better idea to just create a TCP server for the helper functions, instead of a more complex HTTP server, but this would have
required writing a custom protocol for handling the client “preferences” in the kind of messages they would like to see.
As it stands, the user of the helper functions can pass a filtering function that can adjust its behavior based on the
client HTTP request. This is exploited in the logstash-specific helper function by letting the client specify the list
of message types he would like to see in the URL.
As a side note, there have been quite a few improvement and bug fixes in language-puppet since last time I blogged
about it. There still are a few issues to close before releasing a new version.
I did not announce the 0.10.2 version, which was mainly a bug fixing release and the first time I bothered to fix the
dependencies of the language-puppet package. This version is full of new stuff however, you can get it on hackage
or as binaries.
Hiera support, with facts manipulation utilities
This is the main attraction to this release. I did not use Hiera beforehand, so the development only started because of
a GitHub issue. It turns out that this is really a great feature ! Most Hiera features should be supported (actually, I
think all of them are, but I might have missed something). Facts manipulation is also easier now.
You can now have that kind of sessions :
session.sh
123456
$ ssh remote.node 'facter --yaml' > /tmp/facts.yaml # Retrieve facts from a remote host.$ vi /tmp/facts.yaml # Edit the facts so as to test variations.$ puppetresources -p ~/gits/puppet -o remote.node \ --yaml ~/gits/puppet/hiera.yaml \ # Load the given yaml file. --facts-override /tmp/facts.yaml # Override collected facts with# those from the remote host.
New stateWriter monad
I previously blogged about a replacement for the standard RWS monad, wrote a
package, and moved to it. Code speed increased by 10% on a single run,
but I expect subsequent runs to go twice as fast. I will need to benchmark this of course, but this is currently not a
priority.
JSON output, for use with puppet apply
This is a funny feature. There is support for this in puppetresources, with the --json flag. Once this is generated,
you can copy the file onto a machine and apply it with puppet apply --catalog. This also means that it is now trivial
to write a replacement for the puppetmaster, a feature that was experimental before the
full rewrite, but that might be fully supported (with debian
packages) soon.
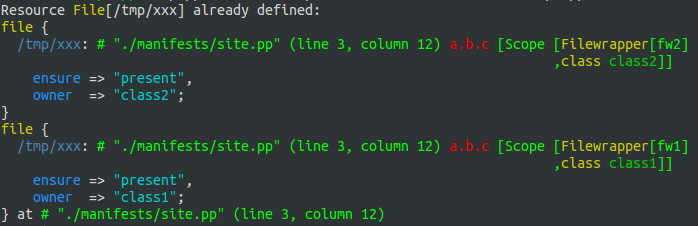
Full scope tracking for all resources
Now all resources are stored with the full ‘scope’ (think of it as some kind of stack trace, including the originating
host for exported resources), which makes debugging much easier. A typical use case is resource duplication in a
define, such as the following case situation :
Error: Duplicate declaration: File[/tmp/xxx] is already declared in file \
/tmp/x/manifests/site.pp:3; cannot redeclare at /tmp/x/manifests/site.pp:3
on node a.b.c
The language-puppet error message is :
This error message is way more informative :
The resources are fully displayed, including all attribute values, which might shed some light on the problem.
The originating host (a.b.c) is displayed. This is crucial for debugging exported resource collisions.
The standard output also shows
Various stuff
There are also a few minor changes in this release :
Support for the $classes variable in templates : this one is just as limited as the official one, as its value is
parse-order dependent.
Support for @instance variables in templates.
Support for scope['key'] syntax in templates.
The haddocks were updated for some modules.
New is_virtual fact, and stdlib functions (flatten, str2bool, validate_absolute_path).
I recently saw comments stating that the Writer (and thus RWS) monad is slow and leaky. I have several programs and libraries built around the RWS monad, where I use the writer part only for logging (that is, snocing a single element at the end of the log), and already noticed in some cases that the profiler reported up to 80% of the time usage spent doing mappends.
Here is a POC, with a pair of monads I called RSS (for Reader - State - State). They offer an API similar to that of RWS, the only difference being that the writer part is internally riding with the state.
Tests with a (top secret) real program gave a two times speed increase. For language-puppet, it is a 10% speed increase for a single run, but most of the time is dominated by the initial parsing, so I expect the gain to be more substantial for other type of applications (complex tests come in mind). I wrote a benchmark, that compares the lazy and strict versions of the RSS and RWS monads, using several distinct monoids as the writer type. Here are the results on my machine :
RSS.Lazy
RSS.Strict
RWS.Lazy
RWS.Strict
Seq
193 µs
194 µs
4.95 ms
457 µs
[]
4.46 ms
4.47 ms
4.89 ms
538 µs
Vector.Prim
764 µs
784 µs
47.72 ms
47.46 ms
RevList
173 µs
175 µs
10.57 ms
5.60 ms
IntSet
187 µs
184 µs
4.98 ms
472 µs
DList
177 µs
176 µs
4.56 ms
302 µs
RevList is the best data structure for my use case (it is just a newtype around a regular list, with reverse applied when the list is extracted), which should not come as a surprise. What was surprising (to me) is how terrible it turns out to me under RWS …
The performance of Vector.Prim with the RWS monad is terrible. I suppose this is due to some optimization rule that could not be deduced in that case. I was however surprised at the good performance compared to lists in the RSS case.
The RSS version is much faster than the RWS one … except for lists !
The strict version of the RSS monad doesn’t have a leaky writer (test here).
I also added a tellElement helper function that would snoc an element to the writer (with suitable monoids) :
tell
tellElement
Seq
193 µs
231 µs
List
4.46 ms
4.45 ms
RevList
173 µs
200 µs
It seems that, to my surprise, there is a small price to pay for calling snoc instead of mappend.
I will probably release this as a package so that I can build language-puppet against it. I will copy’n’paste all the haddocks from the mtl and transformers packages, and move the modules so as to mimick their hierarchy. If you have suggestions, especially concerning the package or module names, strictness properties of the new monads (a subject where I am at loss), please let me know.
Hiera support is now in the latest version of the source repository. This is the last important feature that I wanted
to implement before hitting 1.0. As with all the other features, this was really quick to develop (an evening to write
the Hiera server and integrate it with the interpreter, and two lunch breaks to implement hash, array search types, and
to finalize variable interpolation), and it is mostly untested.
I did not look much at Hiera before, but now that I have learned about it I can see how it will simplify my manifests,
so I’ll test things a bit more during the following days. I’ll also revamp the test library, and, when I’ll be happy
about it, will release 1.0.
I believe several persons are trying to use the library, and I would be quite happy to have feedback about it. If you
need a feature, or a bug fixed, do not hesitate to create an issue.